§ 04.01 · Evaluation
SciAgentGym: Benchmarking Multi-Step Scientific Tool-use in LLM Agents
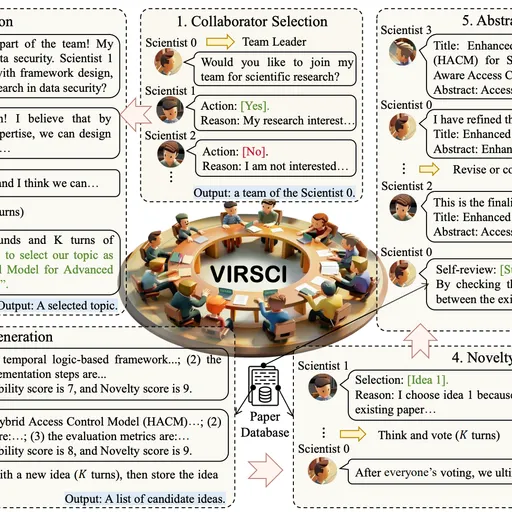
SciAgentGym provides a scalable scientific tool-use environment with 1,780 domain-specific tools, a tiered benchmark for long-horizon agent evaluation, and SciForge for synthesizing logic-aware training trajectories to advance autonomous scientific agents.